A semantic curation engine for film discovery, built on a private, million-title movie knowledge base.
Executive summary
Most movie systems answer: “What are other people likely to watch?”
This system answers: “What kind of movie experience is the user trying to find?”
It is a large-scale movie discovery and curation engine that helps people find films through meaning, mood, cultural context, quality signals, and personal intent — not only title, genre, or keyword matching.
At a simple level, it answers questions like:
- “Find me weird dystopian city movies that feel depressing and massive.”
- “Show me so-bad-it’s-good horror movies from the 80s.”
- “Create a Plex collection of obscure sci-fi movies with cult appeal.”
- “Find movies like The Hitchhiker’s Guide to the Galaxy, but more absurd and less action-oriented.”
The core insight: movie discovery is not just a database search problem. People often search with vague, emotional, cultural, or subjective language. Traditional systems struggle because they lean on genres, popularity charts, and collaborative filtering. This platform combines enriched metadata, semantic embeddings, lexical search, rating intelligence, popularity/obscurity controls, and (on the roadmap) an LLM-driven tuning layer that translates human intent into retrieval strategy.
The result is a system that can behave less like a search box and more like a knowledgeable film curator — especially once automatic tuning sits in front of the engine.
Strategic positioning: a semantic curation platform over a constructed movie knowledge base — not merely a search site, and not a traditional recommender.
The problem
Users search with intent, not metadata
People rarely arrive with clean filters. They arrive with feelings, references, eras, tones, and cultural categories:
| User language | What they actually want |
|---|---|
| “Depressing movies in giant dystopian cities” | Atmosphere, scale, tone, setting — not the word “city” in the title |
| “Best comedies of the 80s” | Hard decade constraint + genre + high ratings + cultural prominence |
| “So bad it’s good” | Low credible ratings, high awareness, unintentional comedy, cult notoriety |
| “Hidden gems in my Plex library” | Personal inventory overlay + quality + obscurity |
A single fixed ranking algorithm fails because the correct balance of signals changes with intent.
Incumbent tools optimize the wrong objective
| System type | Typical objective | Weakness for subjective discovery |
|---|---|---|
| Streaming recommenders (Netflix, etc.) | Maximize engagement on catalog they license | No long-tail obscure titles; no “vibe” queries; no personal library semantics |
| Database search (TMDB, IMDb browse) | Exact metadata match | Poor at mood, metaphor, cultural framing |
| Letterboxd / community lists | Human curation at scale | Requires cinephile literacy; lists go stale; not generative |
| Plex/Jellyfin built-in search | Title/metadata in your files | Weak semantic discovery; collection building is manual |
Gap: there is no widely available product that combines million-title coverage, semantic retrieval, intent-aware ranking, and personal library overlay in one self-hosted or API-first platform.
What the system is
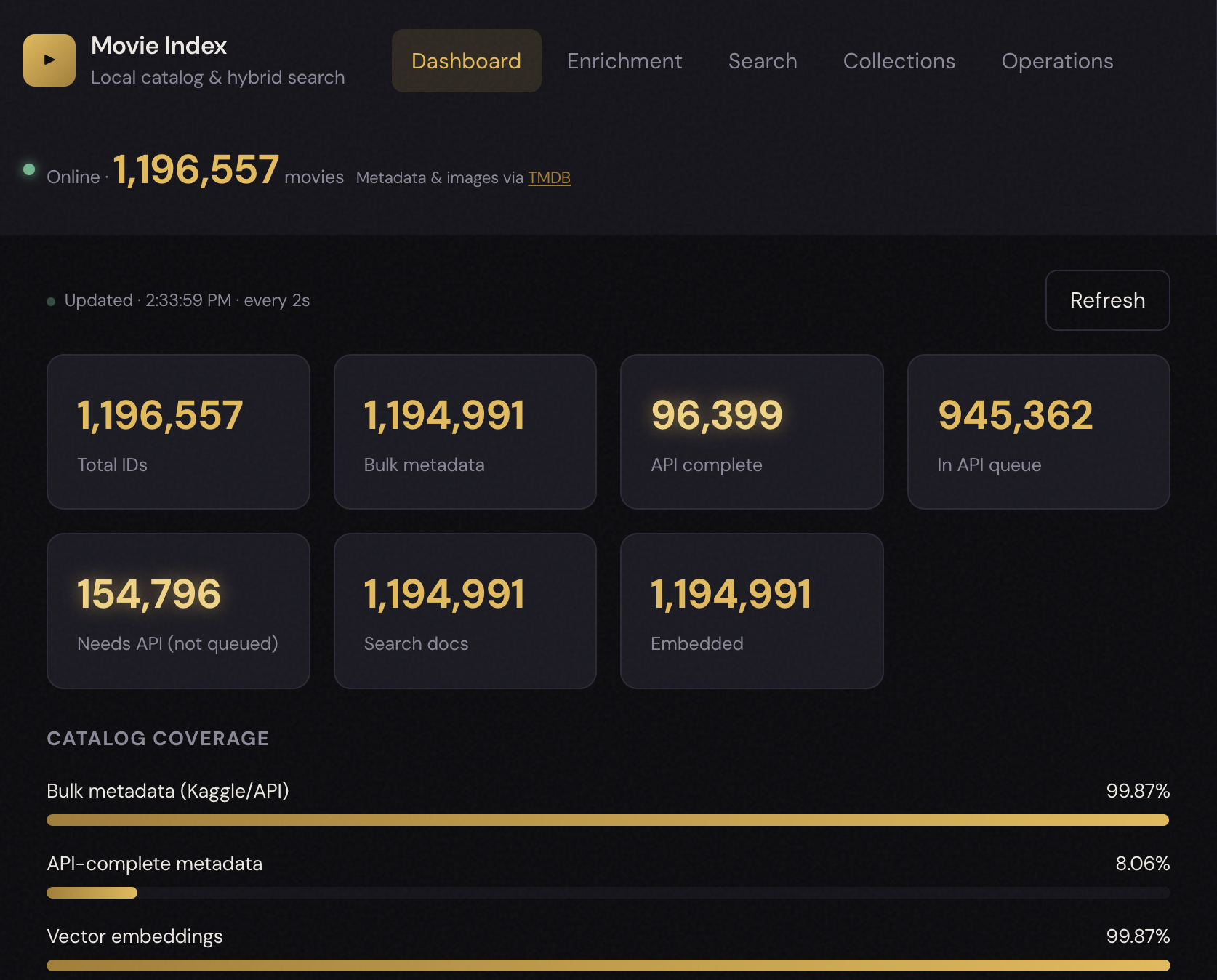
Movie Index (internal project name) is a locally hosted movie intelligence platform:
- It builds and owns a private movie catalog (~1.2M+ TMDB identities; bulk snapshots can exceed 1.4M rows when importing large CSV archives).
- It enriches records from TMDB (and optional bulk sources), indexes them for hybrid search, and serves ranked results via HTTP API and web UI.
- It optionally overlays a user’s Plex library so discovery can mean “from the whole world” or “from what I already own.”
One-line definition:
A semantic curation engine that turns fuzzy human intent into tunable retrieval over a very large, normalized movie knowledge base.
What makes it different
Different question, different product
| Traditional recommender | This system |
|---|---|
| “What will people like me watch next?” | “What experience is the user trying to find?” |
| Optimizes engagement on a licensed catalog | Optimizes interpreted intent on a comprehensive catalog |
| Opaque matrix factorization / trending | Explainable ranking signals (semantic match, lexical match, rating, notoriety, obscurity) |
| Weak on “so bad it’s good,” cult context, atmosphere | Designed for multi-objective discovery (quality, trash, fame, hidden) |
Tunable retrieval, not one algorithm
The engine exposes adjustable fusion weights and cutoff strategies so the same query infrastructure can serve opposite goals:
| User goal | Retrieval emphasis (conceptual) |
|---|---|
| Famous and good | High ratings, high vote count (notoriety), tighter similarity |
| Obscure and good | High ratings, low vote count (obscurity), semantic breadth |
| Famous and terrible | Low Bayesian-adjusted quality, high notoriety |
| Cult / “so bad it’s good” | Trash-quality signal + notoriety + cultural/contextual semantics (roadmap: dedicated embedding space) |
| Thematic / mood | Semantic similarity, relaxed lexical title match, elbow-based membership |
Key differentiator (product): an automatic curation layer (planned) that sets these knobs from natural language so casual users never see them.
Business opportunities
Each opportunity below reuses the same core: catalog + embeddings + hybrid search + ranking + (optional) library overlay.
Consumer movie discovery app
Product: Public or freemium web app — “describe the movie you want.”
Example queries:
- “Movies that feel like lonely neon cities at night.”
- “Absurd British sci-fi comedies.”
- “Forgotten 90s thrillers that are actually good.”
- “Bad movies that are fun, not just bad.”
Positioning: Competes with discovery and exploration (Letterboxd-adjacent browsing, film Twitter/list culture, niche cinephile search) — not with Netflix-style “what to stream tonight on our platform.”
Differentiator: Users do not need to know filters, genres, or metadata vocabulary. They describe vibe, era, tone, or cultural category; the system translates that into retrieval strategy.
Monetization paths: subscription, affiliate links (where legally appropriate), premium collections, API tier for power users.
Plex / Jellyfin collection generator
Product: Connect to a user’s media server; generate curated collections from natural language.
Example queries:
- “Build a cult sci-fi collection from my library.”
- “So-bad-it’s-good movies I already own.”
- “1980s creature-feature playlist.”
- “Hidden gems I forgot I had.”
Why this niche is strong:
- Users already maintain large personal libraries and care about organization.
- They are underserved by semantic discovery inside Plex/Jellyfin.
- No streaming of copyrighted content required — only metadata analysis and collection instructions returned to the local server.
Technical fit today: Plex sync marks in_library on catalog rows; search and collections APIs accept in_library: true filters. Jellyfin would be a parallel integration.
Monetization paths: one-time license, subscription plugin, homelab “pro” tier.
Movie metadata and semantic search API
Asset: A constructed, normalized, embedded catalog — not raw TMDB dumps.
Potential API customers:
- Indie app developers
- Recommendation startups
- Plex/Jellyfin plugin authors
- Film researchers and educators
- AI application builders
- Media catalog / metadata companies
- Hobbyists building local movie tools
API capabilities (existing or near-existing):
| Capability | Description |
|---|---|
| Normalized metadata | Title, year, overview, genres, keywords, cast, crew, ratings, posters |
| Hybrid search | Semantic + lexical + metadata filters in one request |
| Similarity / “more like this” | Same embedding space as search |
| Saved collections | Store query + filters; re-resolve on demand |
| Library overlay | Restrict to in_library for personal-server use cases |
| Scoring transparency | Per-hit scores: semantic similarity, RRF, Bayesian rating, etc. |
Positioning: A “semantic layer” on top of movie metadata — the hard data engineering and embedding work already done.
Monetization paths: usage-based API, tiered keys, enterprise license, white-label.
Precomputed embedding dataset
Problem: Generating embeddings for 1M+ movies is expensive, slow, and operationally painful (GPU batching, model versioning, index rebuilds).
Product: Licensed dataset bundles:
- Movie identity (TMDB ID, title, year, etc.)
- Plot/metadata embedding vectors
- (Roadmap) Historical/cultural context embeddings
- Similarity index metadata / version documentation
- Incremental update packages when the model or enrichment changes
Buyers: AI developers who want movie search or recommendations without building the pipeline.
Automated editorial and content marketing
Because the engine can surface clusters, outliers, and thematic slices, it can power:
- Listicles (“Weirdest low-budget 90s sci-fi”)
- Newsletter segments
- SEO landing pages
- Social content calendars
Examples:
- “Movies that accidentally became cult classics”
- “Dystopian city films before and after Blade Runner”
- “The best bad shark movies you’ve never heard of”
Monetization paths: ad-supported media property, B2B content tooling for publishers, lead gen for a consumer app.
Technical platform
This section covers architecture and implementation for readers who need credible technical depth — and for technical partners evaluating feasibility.
Architecture at a glance
flowchart TB
subgraph external [External — ingestion only]
TMDB_EXP[TMDB Daily ID Exports]
TMDB_API[TMDB API v3]
KAGGLE[Kaggle TMDB CSV snapshot — optional bulk]
PLEX[Plex server — optional]
end
subgraph server [Single-server deployment — Docker Compose]
API[FastAPI + Uvicorn — port 8080]
WORKER[Enrichment worker — continuous]
CLI[movie-index CLI / cron]
subgraph data [PostgreSQL 16 + extensions]
META[Constructed metadata — ~1M+ rows]
FTS[Full-text search — tsvector + GIN]
TRGM[Trigram title match — pg_trgm]
VEC[Vector index — pgvector HNSW]
QUEUE[Enrichment queue + phase tracking]
COLL[Saved collections]
end
MODELS[Local model cache — Hugging Face weights]
ARTIFACTS[Poster cache — local disk]
end
TMDB_EXP --> CLI
TMDB_API --> WORKER
KAGGLE --> CLI
PLEX --> API
CLI --> META
WORKER --> META
META --> FTS
META --> VEC
API --> FTS
API --> VEC
API --> TRGM
MODELS --> VEC
Design principle: At query time, the system reads only PostgreSQL and local files — not TMDB, not cloud embedding APIs. External services are used during ingestion and sync only. That yields predictable latency, offline-capable search (once built), and no per-query SaaS inference bill.
Software stack
| Layer | Technology | Role |
|---|---|---|
| Database | PostgreSQL 16 | System of record for all metadata, queues, collections |
| Vector search | pgvector (HNSW, cosine distance) | Semantic nearest-neighbor on filtered candidate sets |
| Lexical search | PostgreSQL FTS (tsvector, websearch_to_tsquery) |
Overviews, keywords, assembled search documents |
| Fuzzy titles | pg_trgm | Typo-tolerant and partial title matching |
| API | FastAPI + Uvicorn | REST: search, movies, collections, Plex sync, dashboard |
| Runtime | Python 3.12+ | Ingestion, search fusion, embedding jobs, CLI |
| Embeddings | sentence-transformers | Local bi-encoder; batch on CPU, Apple MPS, or NVIDIA CUDA |
| Packaging | Docker Compose | postgres, api, worker services |
| CLI | Click (movie-index command) |
Operations, imports, enrichment, embedding, stats |
Deliberate non-choices (v1): No Elasticsearch, Pinecone, or managed vector DB — one database reduces operational cost for homelab and early commercial pilots.
Data sources and catalog construction
No single upstream provider ships a complete, query-ready movie database. The platform merges sources into one constructed catalog:
| Source | What it provides | How it is used |
|---|---|---|
| TMDB Daily ID Exports | Near-complete daily list of valid TMDB movie IDs + export-level popularity | Catalog spine — hundreds of thousands to ~1M+ IDs without months of API paging |
| TMDB API v3 | Full detail: overview, genres, keywords, credits, images, external IDs | Enrichment for searchable depth; rate-limited queue (~4 req/s default, configurable) |
| Kaggle TMDB snapshot (optional) | Bulk CSV (~930k–1.4M rows) with core metadata | Fast bulk bootstrap; API queue backfills gaps |
| Plex (optional) | User’s owned titles | in_library overlay only — not a metadata source of truth |
| IMDb datasets (optional, roadmap) | Supplemental ratings / crosswalk | Offline import; non-commercial license constraints |
Scale targets:
- ~1.2 million movie identities from TMDB export workflow (project design target).
- ~1.42 million rows available in bundled Kaggle CSV snapshot (useful for bulk import and gap-fill).
- Enrichment at 4 TMDB requests/sec ≈ 3–4 days of continuous worker time for a full API detail pass over ~1.2M IDs (order-of-magnitude planning number).
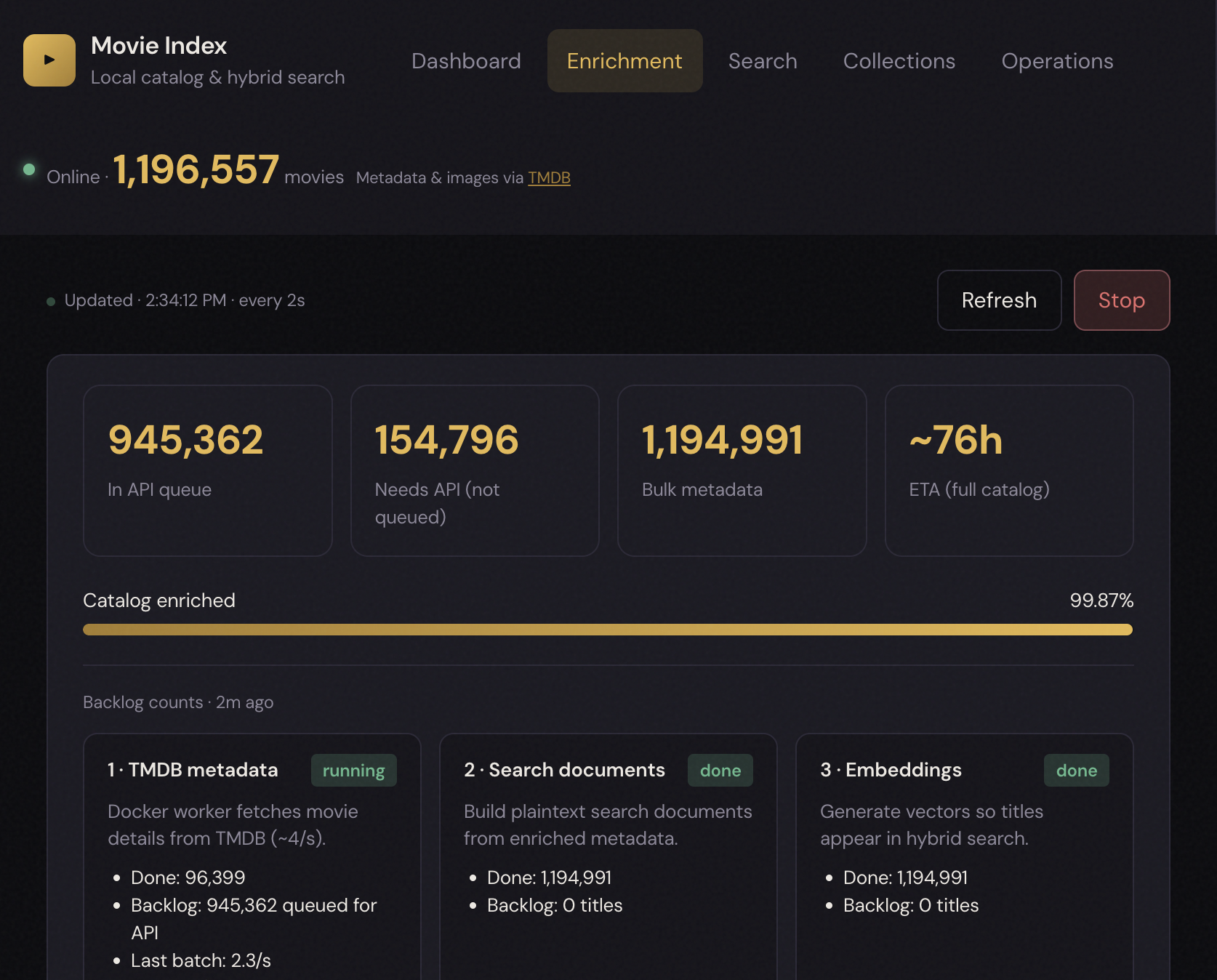
Enrichment pipeline (automated):
- Import IDs (export and/or Kaggle).
- Queue movies for TMDB API detail fetch (priority: in-library first, then popularity).
- After each batch: build search documents and embedding vectors (configurable
ENRICHMENT_AUTO_INDEX). - Track per-movie enrichment phases: catalog spine → core metadata → poster media.
Stored metadata per movie (representative):
- Identity: TMDB ID, IMDb ID, titles, release date/year
- Text: overview, tagline, search document (derived)
- Facets: genres, keywords (JSON arrays)
- People: cast (top billed), crew (directors/writers)
- Franchise: collection id/name
- Signals: popularity, vote_average, vote_count, adult flag
- Media: poster paths, locally cached poster files
- Library:
in_libraryboolean - Provenance:
detail_fetched_at,search_doc_built_at, enrichment phase status
Search document and embedding model
Search document (today): A single composed text block per movie used for both FTS indexing and embedding input:
- Title, original title, year, tagline, overview
- Genres, keywords (capped), top cast, directors
- Collection name
Embedding model (current default):
| Setting | Value |
|---|---|
| Model | Qwen/Qwen3-Embedding-0.6B |
| Dimensions | 1024 |
| Storage | movie_embeddings table with embedding_model + embedding_version for traceability |
| Index | HNSW on cosine distance (<=> operator) |
| Alternatives (supported) | BAAI/bge-small-en-v1.5 (384d), bge-base, bge-large, bge-m3, nomic-ai/nomic-embed-text-v1.5 |
Models run entirely locally — weights cached under data/models/. No OpenAI/Cohere-style per-query embedding fees.
Hardware: Auto-detects CUDA → Apple MPS → CPU. Docker worker/API containers typically use CPU; native runs on Apple Silicon can use MPS for faster embedding batches.
Roadmap — second embedding space (“cultural / context”):
Planned separate representation for production history, reception, cult status, trivia, and “why this movie matters” — critical for queries like “so bad it’s good” where plot text is insufficient. Not yet implemented; today all semantic search uses the plot/metadata document embedding.
Hybrid retrieval pipeline
For each query, the engine:
- Embeds the query with the same model (query-specific encoding per model family — e.g. Qwen uses a
queryprompt name). - Runs lexical branch:
- PostgreSQL FTS rank on
search_tsv(websearch_to_tsquery, English). - Trigram similarity on title (threshold > 0.2).
- PostgreSQL FTS rank on
- Runs semantic branch:
- pgvector top-K by cosine distance on
movie_embeddings, respecting SQL filters.
- pgvector top-K by cosine distance on
- Fuses lexical + semantic candidate lists with Reciprocal Rank Fusion (RRF) — default
k = 60. - Applies weighted score fusion across multiple signals (see below).
- Optionally applies membership cutoff (how many results “belong” in the set).
sequenceDiagram
participant User
participant API
participant Encoder
participant PG as PostgreSQL
User->>API: Natural language query + filters
API->>Encoder: Embed query locally
Encoder-->>API: Query vector (1024-d)
par Lexical
API->>PG: FTS + trigram title search
and Semantic
API->>PG: pgvector HNSW nearest neighbors
end
PG-->>API: Candidate pools (e.g. top 500 each)
API->>API: RRF merge + weighted scoring + cutoff
API-->>User: Ranked hits + explainable scores
Ranking dimensions
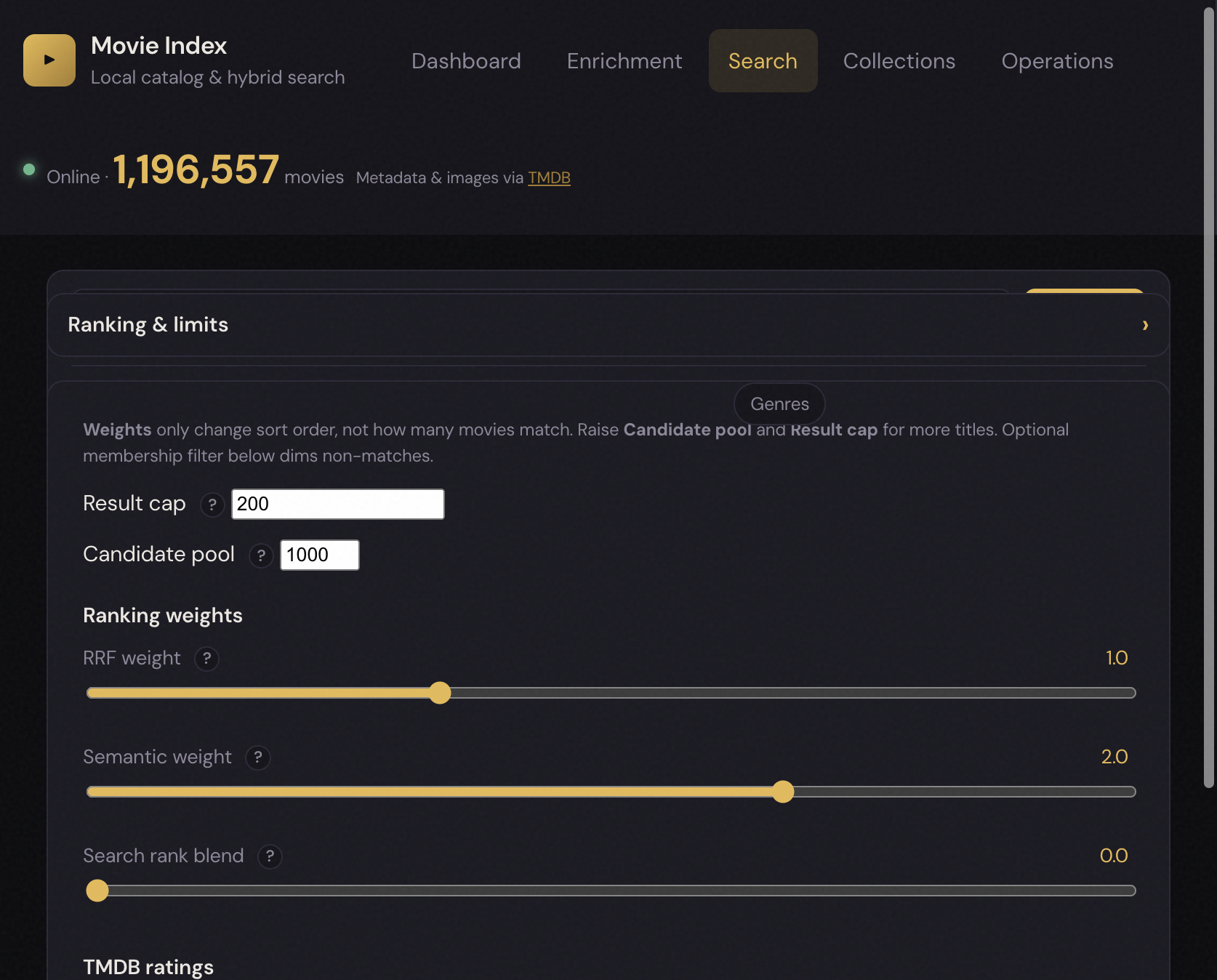
The API accepts a ScoringConfig with fusion weights (0–10 scale) and rating/cutoff settings:
| Signal | Meaning | Example use |
|---|---|---|
| RRF | Reciprocal rank fusion across lexical + semantic lists | Default hybrid balance |
| Semantic | Vector similarity (1 − cosine distance) | Mood, theme, atmosphere queries |
| Search rank | Combined channel rank score | Fine-tuning lexical vs semantic emphasis |
| Rating high | Bayesian-shrunk quality (normalized) | “Actually good” lists |
| Rating low (“trash”) | Inverse of quality signal | “So bad it’s good” |
| Notoriety | log1p(vote_count) — famous / widely rated |
Mainstream, infamous, cult-famous |
| Obscurity | Inverse of notoriety | Hidden gems, deep cuts |
Bayesian rating:
Raw TMDB vote_average is misleading for low vote_count. The system shrinks ratings toward a catalog mean (configurable prior, default 50 pseudo-votes) so that:
- “1.5 stars from 3 people” does not dominate “3.8 stars from 80,000 people.”
Reversing the quality signal (boost rating_low) surfaces titles that are credibly poorly rated at scale — a key ingredient for “so bad it’s good.”
Membership cutoff modes:
| Mode | Behavior |
|---|---|
none |
All ranked results count |
top_n |
Fixed cap |
threshold |
Minimum semantic (or other) score |
elbow |
Largest gap in score curve — auto-sized collections |
Elbow mode addresses: “Chupacabra movies” (tight cluster) vs “dreamlike loneliness” (broad semantic spread) without always returning exactly 100 or 200 titles.
Metadata filters
SQL-level constraints applied before or during retrieval:
| Filter | Use case |
|---|---|
year_min / year_max |
Decade constraints (“80s comedies”) |
genres |
Genre enforcement |
in_library |
Plex-only discovery |
enriched_only |
Require full TMDB detail |
min_vote_count / max_vote_count |
Obscurity vs notoriety control |
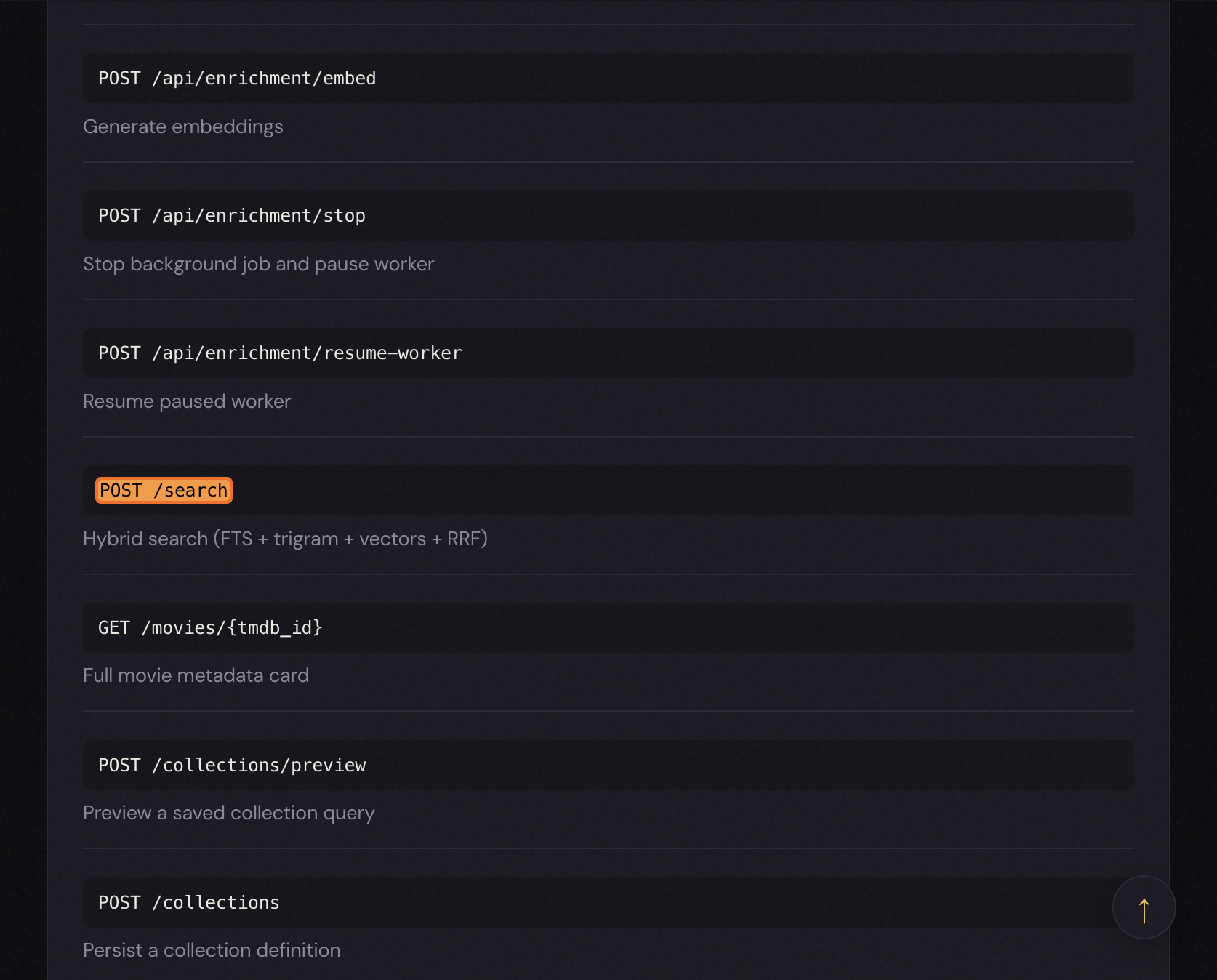
API surface
| Method | Endpoint | Purpose |
|---|---|---|
| GET | /health |
Liveness + DB stats |
| GET | / |
Web dashboard (search, enrichment ops, stats) |
| GET | /api/dashboard |
Pipeline stats, sync state |
| POST | /search |
Hybrid search with filters + scoring config |
| GET | /movies/{tmdb_id} |
Full metadata card |
| POST | /collections/preview |
Preview a collection query |
| POST | /collections |
Save a collection definition |
| GET | /collections/{id}/movies |
Resolve saved collection |
| GET | /api/plex/status |
Plex config + library counts |
| POST | /api/plex/sync |
Refresh in_library from Plex |
Optional X-API-Key when API_KEY is set — suitable for LAN or partner pilots.
Example search request:
{
"query": "depressing giant dystopian city",
"limit": 50,
"filters": { "year_min": 1970, "in_library": false },
"scoring": {
"weights": { "semantic": 2.0, "rrf": 1.0, "obscurity": 0.5 },
"cutoff_mode": "elbow",
"cutoff_on": "semantic"
}
}
Plex integration
- Config:
PLEX_BASE_URL,PLEX_TOKEN, optionalPLEX_LIBRARY_NAME. - Sync lists movie libraries, extracts TMDB/IMDb GUIDs, matches to catalog, sets
in_library. - Priority boost: titles in the user’s library are enriched and indexed first.
- Search UI defaults can restrict to library-only for “what should I watch from what I own?”
Jellyfin: Not implemented; the same overlay pattern applies.
How discovery works (end-to-end)
Example A — Thematic / mood query
User: “Depressing movies that take place in giant dystopian cities.”
Ideal retrieval plan (manual today; automatic via LLM later):
| Knob | Setting |
|---|---|
| Semantic weight | High |
| Lexical / title | Lower (avoid “city” in title dominating) |
| Filters | Optional sci-fi / thriller genres; year range if implied |
| Rating signals | Neutral (not optimizing for “best”) |
| Cutoff | Elbow on semantic similarity |
| Candidate pool | Broad (e.g. 500+) |
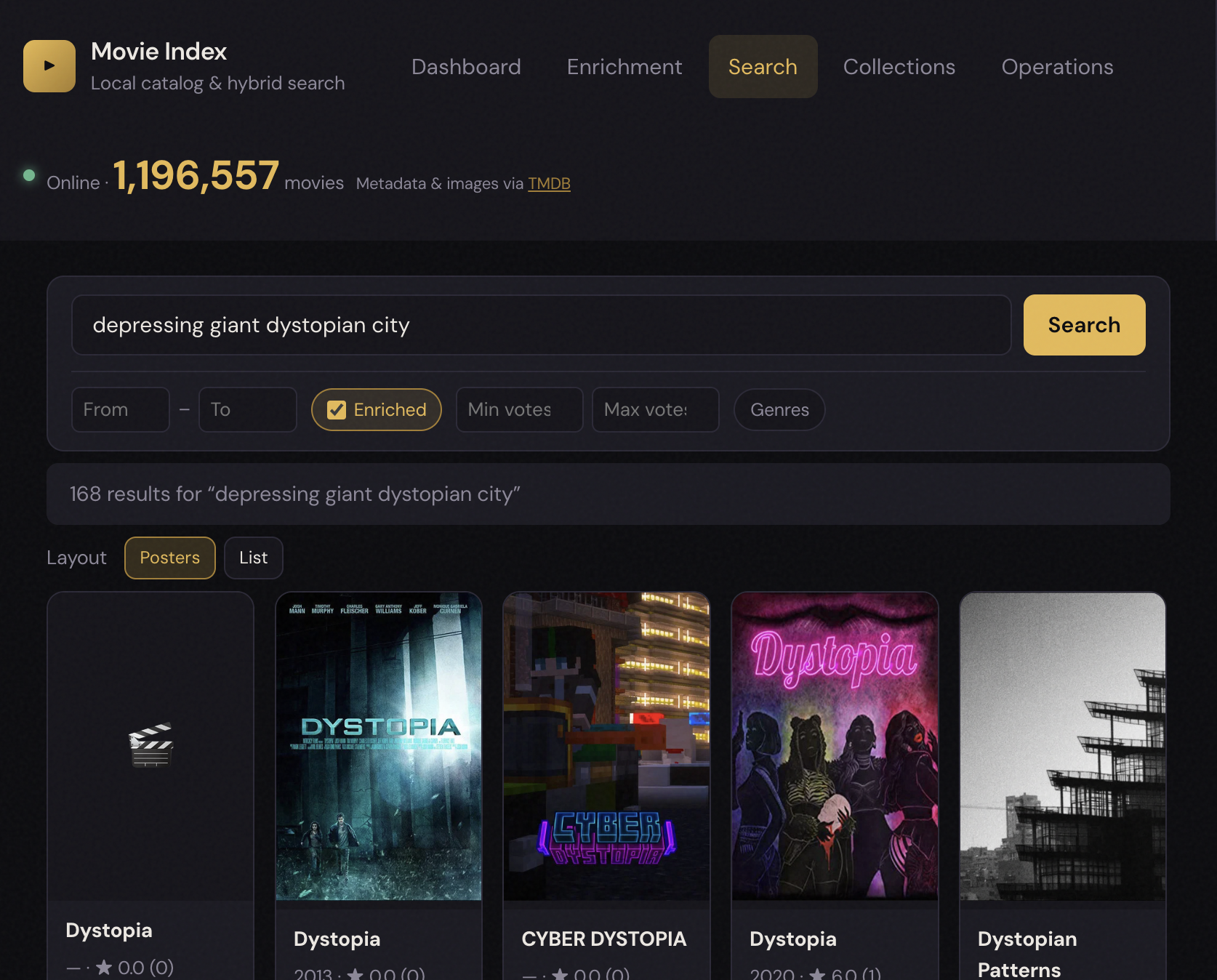
Example B — Canon / best-of query
User: “Best comedies of the 80s.”
| Knob | Setting |
|---|---|
year_min / year_max |
1980–1989 |
genres |
Comedy |
| Rating high + notoriety | High |
| Obscurity | Low |
| Lexical | Moderate (decade + genre terms) |
| Cutoff | Higher top-N or threshold |
Example C — “So bad it’s good”
User: “Funny-bad horror from the 80s.”
| Knob | Setting |
|---|---|
| Filters | Horror; 1980–1989; min_vote_count to ensure credibility |
| Rating low (trash) | High |
| Notoriety | Moderate–high |
| Semantic | Theme + (roadmap) cultural/context embedding |
| Bayesian logic | Ensures “bad” means many voters, not data noise |
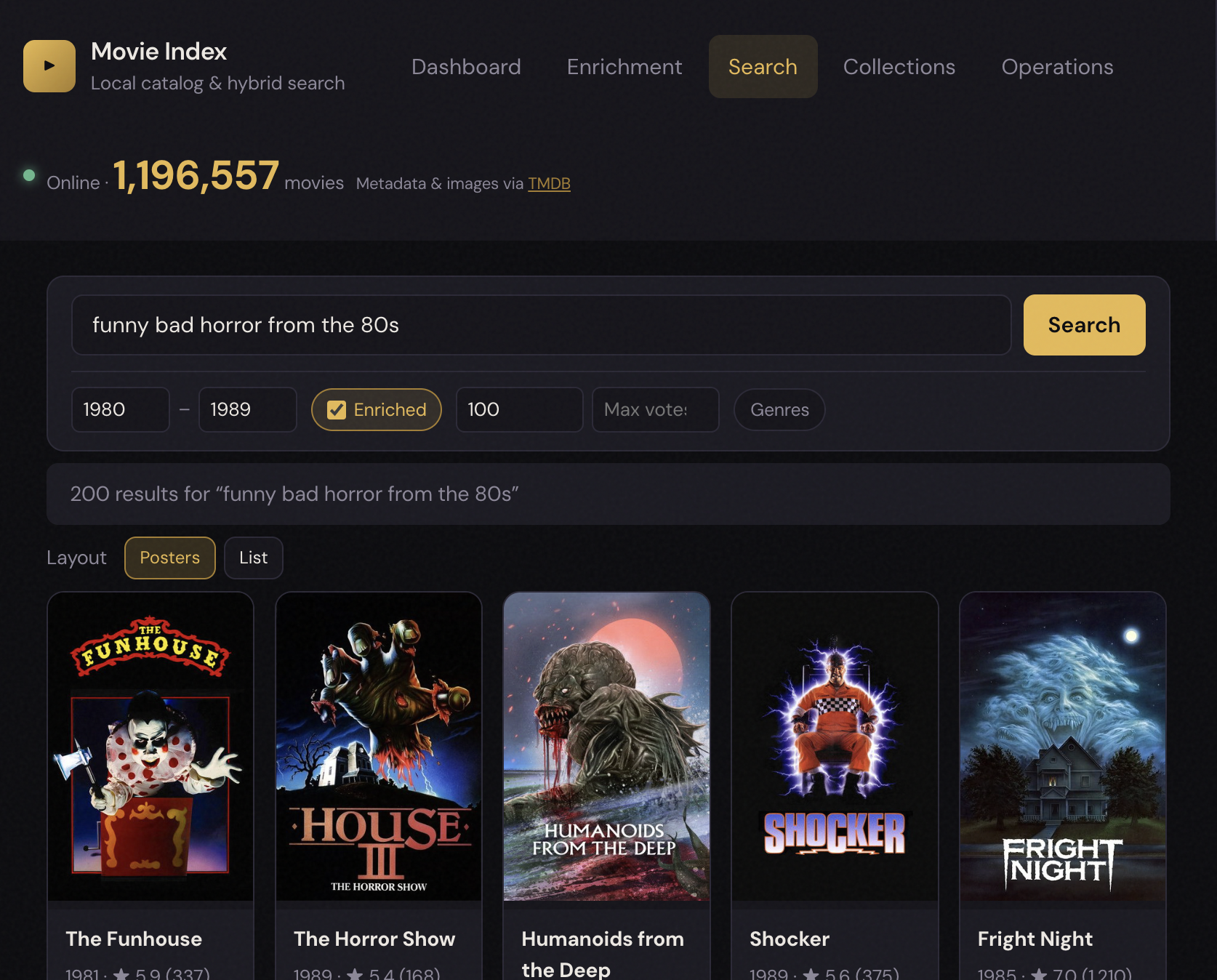
Example D — Hidden gems
User: “Forgotten films that are actually good but not famous.”
| Knob | Setting |
|---|---|
| Rating high | High |
| Obscurity | High |
| Notoriety | Low |
| Semantic | Moderate–high |
| Cutoff | Elbow |
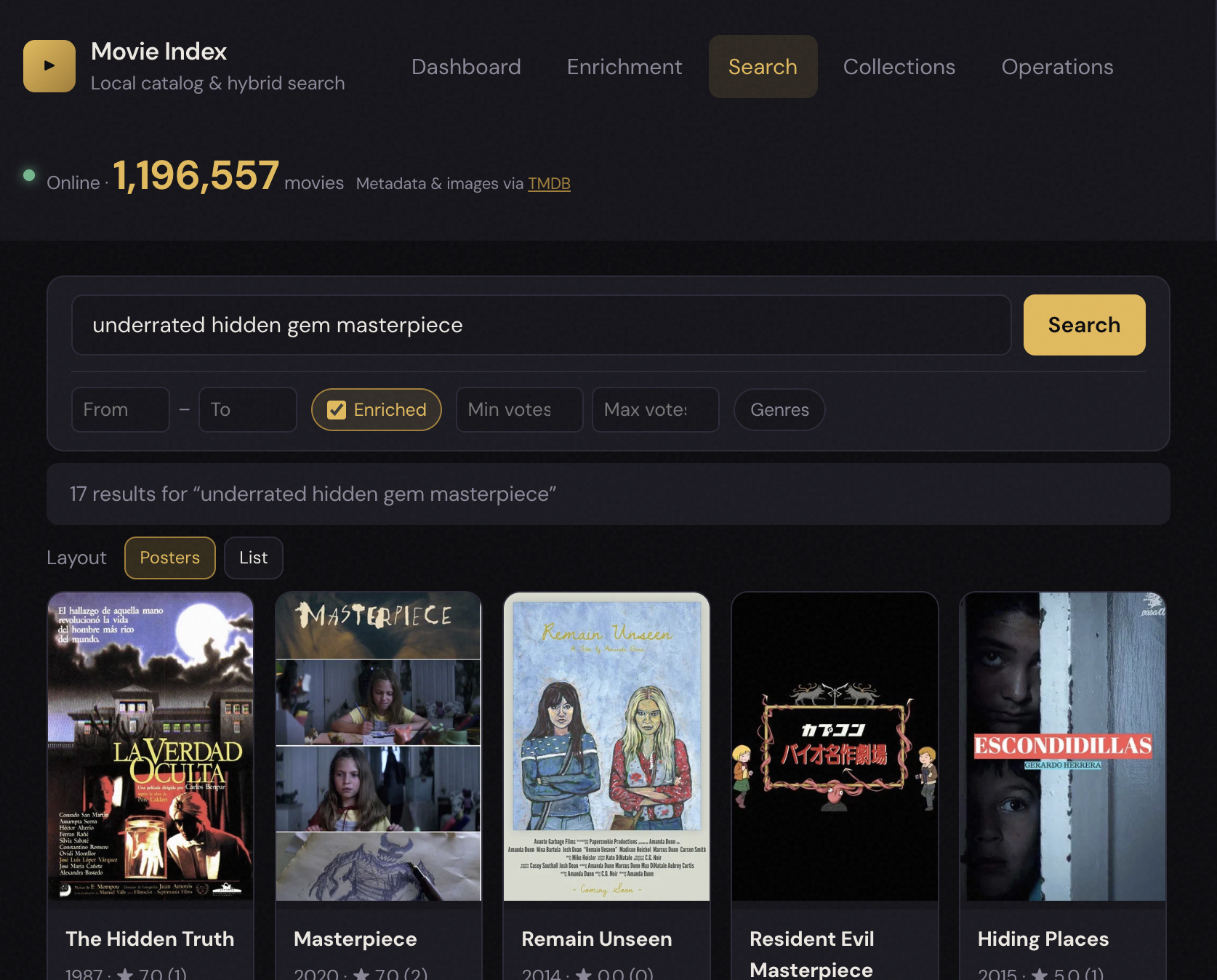
Conversational refinement (roadmap)
Multi-turn dialogue adjusts the same knobs:
- “Too many movies with ‘city’ in the title” → reduce lexical/title weight, increase semantic.
- “Darker and less mainstream” → increase obscurity, decrease notoriety, refine semantic query expansion.
The user steers like talking to a film expert — without operating a control panel.
Built today vs roadmap
Honest status framing for partners and investors. Screenshots in this post are from a TMDB-scale catalog (~1.2M titles) and intentionally omit personal-library overlays and media-server sync — those are optional deployment features, not required for semantic discovery.
Built and operational
| Capability | Notes |
|---|---|
| Million-scale catalog ingestion | TMDB export + API queue + optional Kaggle bulk |
| Continuous enrichment worker | Docker worker service; auto search-doc + embed |
| Hybrid search (FTS + trigram + pgvector + RRF) | Production code path |
| Multi-signal weighted ranking | Rating high/low, notoriety, obscurity, Bayesian shrinkage |
| Cutoff modes | none, top_n, threshold, elbow |
| Saved collections API | Preview, persist, resolve |
Plex in_library sync |
Library-first enrichment priority |
| Web dashboard | Search, scoring sliders, enrichment controls, ops |
| Self-hosted deployment | Docker Compose; portable data/ directory |
| Local embeddings | No cloud inference dependency |
| Model registry | Switch embedding model with versioned vectors |
In progress / partial
| Capability | Notes |
|---|---|
| Full catalog enrichment | ~1.2M API passes take days; many rows may be spine-only until enriched |
| Poster local cache | Pipeline exists; coverage grows with enrichment |
| Cross-encoder rerank | Flag in API (use_rerank); not wired in search path yet |
Roadmap (high value, not yet built)
| Capability | Business impact |
|---|---|
| LLM automatic curation layer | Makes product usable by non-experts; core GTM unlock |
| Second embedding space (cultural/context) | Unlocks “so bad it’s good,” cult, production-history queries |
| Conversational refinement | Retention and differentiation vs static search |
| Jellyfin integration | Same market as Plex plugin |
| Cross-encoder rerank | Precision boost for top results |
| Query → filter LLM parser | Natural language to SQL filters (year, genre) |
| Static collection export | Push lists to Plex/Kodi/CSV acquisition workflows |
| IMDb supplemental import | Richer ratings crosswalk (license-dependent) |
Deployment and data ownership
Self-hosted first
- Typical deployment: one server (homelab Mac mini, NAS VM, small cloud VM).
- All data under
MOVIE_INDEX_DATA_DIR(default./data): Postgres files, exports, models, posters, backups. - Moving hosts: copy repo +
.env+ entiredata/tree — no re-embedding required.
Why self-hosted matters commercially
| Stakeholder | Benefit |
|---|---|
| Power users / Plex community | Data stays on LAN; no upload of library titles to a third party |
| Enterprise pilots | Air-gapped or VPC deployment possible |
| API business | Offer hosted API or on-prem license from the same codebase |
Hosted SaaS (future)
A hosted tier is compatible with the architecture but is a go-to-market choice, not a technical requirement. TMDB attribution and API terms must be reflected in any public UI.
Competitive context
| Alternative | Strength | Gap this system fills |
|---|---|---|
| TMDB / IMDb search | Complete metadata, trusted IDs | Weak subjective/vibe search; no personal library semantics |
| JustWatch, Reelgood | Streaming availability | Not built for obscure/cult/long-tail curation |
| Letterboxd | Community taste graph | Requires social graph and manual list culture |
| Plex Discover | Convenience inside Plex | Limited semantic discovery; no cross-catalog “describe vibe” |
| General RAG over Wikipedia | Flexible | Expensive, inconsistent, no structured rating/obscurity controls |
| Pinecone + raw TMDB embeddings DIY | Custom | Months of pipeline work; no Bayesian/cult ranking logic |
Moat hypothesis: The combination of million-title constructed catalog, hybrid retrieval, intent-aware multi-signal ranking, library overlay, and (when shipped) LLM tuning is harder to replicate than any single component alone.
Risks, dependencies, and compliance
| Area | Consideration |
|---|---|
| TMDB | API key required; rate limits; attribution on public surfaces; terms restrict how data is exposed |
| Enrichment cost | Time and API quota to detail-enrich full catalog |
| Compute | Initial embed of 1M+ titles is GPU/time-intensive (one-time + re-embed on model change) |
| Plex | Token security; read-only library access; matching unmatched titles |
| Copyright | System indexes metadata only; does not host films |
| Model licenses | Qwen/BGE/nomic terms for redistribution if selling embedding datasets |
| IMDb datasets | Non-commercial restrictions if used |
| Product risk | Without LLM auto-tuning, power of engine exceeds mainstream UX |
Recommended near-term product
Strongest near-term wedge: a simple interface —
“Describe the kind of movie you want.”
→ curated list → conversational refinement.
| Layer | Role |
|---|---|
| UX | Natural language in; ranked posters + explanations out |
| Auto-curation (build) | LLM maps utterances → ScoringConfig + filters + cutoff |
| Engine (exists) | Hybrid search + Plex overlay + collections |
| Power user mode (exists) | Advanced sliders in dashboard for tuning and evaluation |
Secondary wedge: Plex collection generator for the homelab community — passionate users, clear pain, willingness to pay for tooling.
Strategic summary
| Dimension | Statement |
|---|---|
| What it is | Semantic curation engine over a private million-movie knowledge base |
| What it is not | A streaming recommender or a basic TMDB clone |
| Core insight | Discovery is multi-objective; intent changes the right ranking strategy |
| Technical foundation | PostgreSQL + pgvector + hybrid RRF + local embeddings + Bayesian rating signals |
| Product unlock | LLM layer that translates human language into retrieval plans |
| Business paths | Consumer discovery, Plex/Jellyfin collections, metadata API, embedding datasets, editorial automation |
| Deployment advantage | Self-hosted, query-time offline, library-aware, explainable scores |
The engine is intentionally complex so the user experience can be simple. The business opportunity is to productize that translation layer — turning a powerful retrieval laboratory into a film discovery assistant that traditional search and recommendation stacks do not provide.
Appendix: query → strategy mapping
| User query | Filters | Weight emphasis | Cutoff |
|---|---|---|---|
| Lonely neon cities at night | — | Semantic ↑, obscurity moderate | Elbow |
| Best 80s comedies | years 1980–1989, genre Comedy | rating_high ↑, notoriety ↑ | top_n |
| So-bad-it’s-good 80s horror | years 1980–1989, genre Horror, min votes | rating_low ↑, notoriety ↑ | Elbow |
| Chupacabra movies | — | Lexical ↑ (rare exact term) | Threshold or small top_n |
| Hidden gems | — | rating_high ↑, obscurity ↑ | Elbow |
| Cult sci-fi deep cuts | genre Sci-Fi | semantic ↑, notoriety moderate | Elbow |
| Hidden gems in my Plex | in_library: true |
rating_high ↑, obscurity ↑ | Elbow |
| Cult sci-fi I own | in_library: true, genre Sci-Fi |
semantic ↑, notoriety moderate | Elbow |